








Dans toutes les branches d’activités, la continuité de la production informatique devient critique. Les plans de reprise se démocratisent autour des fibres noires, de la virtualisation et du Cloud.
« Sans plan de reprise ou de continuité informatique, l’organisation se ferme de nombreux marchés car désormais les appels d’offres réclament aux soumissionnaires qu’ils précisent leurs moyens de secours informatiques mis en place. La technologie pousse dans le bon sens, vers la démocratisation des solutions. Les prix d’acquisition et d’exploitation chutent à travers les offres Cloud, la location de fibre noire ou encore les postes de travail en mode VDI », observe Bruno Hamon, fondateur et directeur associé du cabinet Mirca et chargé de mission à l’Afnor.

Le spécialiste préconise de définir avec les métiers les exigences de continuité d’activité, par rapport à la notion de “promesse client”. Pour cela, il prend en compte trois sinistres principaux dans l’élaboration d’un PCA : des locaux inaccessibles, de façon durable ou non, une perte totale ou partielle du système d’information et un absentéisme important du facteur humain. Un tel plan doit « se construire avec les métiers en y ajoutant la prévention contre les fuites de données et la nécessité d’être en conformité avec le Règlement sur la protection des données personnelles ou RGPD dans l’objectif de bien maîtriser son patrimoine informationnel. Cela inclut les données à caractères personnelles au-delà de son système d’information, dans le Cloud comme chez les hébergeurs. »
Plusieurs risques à anticiper
Les technologies et prestataires de services Cloud relèvent le défi d’une production IT ininterrompue, autour d’offres DRaaS (Disaster Recovery as a Service) notamment : « Depuis deux ans, les CSP (Cloud Service Providers) développent leur propre réseau d’interconnexion entre datacenters, sans passer par les opérateurs. La fibre noire multiplexée facilite ainsi la bascule rapide entre les sites de Paris et Francfort, en cas de sinistre », précise Didier Lavoine, directeur technique, Développement et Innovation de Digora.

On distingue trois types de pannes majeures intervenant au niveau des bâtiments, des équipements logiques ou physiques. Sur site, les incidents météorologiques (orage, grêle ou tempête) peuvent provoquer une coupure d’alimentation électrique, une inondation, un incendie, voire la destruction du datacenter. Un acte de vandalisme, de terrorisme ou une attaque militaire auront des conséquences semblables.
Les pannes de serveurs ou d’équipements réseau sont le plus souvent liées à un composant défectueux (processeur, mémoire, disque, carte réseau). Enfin les pannes logiques ont diverses causes possibles : la cyberattaque, l’effacement maladroit de fichier, un bug dans une application ou la corruption de données numériques.
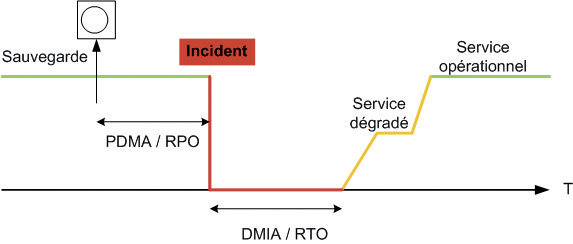
Face à cette variété de sinistres, l’organisation retient souvent plusieurs protections pour limiter l’impact des défaillances. Ce faisant, elle multiplie les interfaces d’administration à prendre en main en situation d’urgence. Le PRA détaille les procédures pour remettre en production les systèmes critiques, pas à pas. Il précise les étapes clés à suivre en cas de crash. Pour le préparer, on place trois repères clés sur une échelle de temps, à commencer par l’heure supposée du sinistre au centre de cette ligne. Deux jalons sont répartis de part et d’autre : à gauche, la PDMA (perte de données maximale admissible) et à droite du sinistre, la DMIA (durée maximale d’interruption admissible) ou DIMA (durée d’indisponibilité autorisée). Ces deux repères peuvent glisser dans le temps, selon la criticité de l’application. Ils s’expriment en minutes, en heures ou en jours, plus rarement en secondes.
Des objectifs propres à chaque plan
Chaque plan de reprise d’activités gagne à établir ses propres objectifs, réalistes, par application. Cette approche fournit la séquence de restauration des applications et données à remettre en production, suivant leur priorité. Dès qu’une nouvelle application apparaît, l’évaluation de son couple PDMA/ DMIA devient nécessaire. De même, tout nouvel équipement actif à peine connecté, un serveur, un firewall ou un routeur rejoindra la liste des matériels à remplacer dans un délai convenu, par une ou plusieurs voies planifiées d’avance (acquisition, échange ou stock).
Un nouveau socle tangible à définir
Lorsqu’un sinistre survient, le temps de réaction de l’organisation conditionne la reprise des activités métiers, donc la poursuite des affaires. « Le PRA n’est pas un simple effet de mode. La dépendance des entreprises au digital est de plus en plus forte, souligne Anwar Saliba, directeur général adjoint d’Euclyde. Le coût de mise en œuvre du plan ne serait pas son principal obstacle : « Les technologies Cloud allègent le coût du PRA, lorsqu’on réserve des ressources sur un site distant, on ne paye qu’en cas de besoin. Nos clients consacrent de 5 % à 10 % de leur budget IT annuel à leur PRA. C’est peu, comparé aux 50 % nécessaires pour un PCA, bâti sur deux datacenters distincts. »

La mutualisation des moyens techniques et le modèle de facturation du Cloud, à l’usage, expliquent la démocratisation du PRA, assuré par une bonne gestion du capacity planning par le prestataire. En effet, la probabilité que tous ses clients déclenchent leur PRA en même temps reste proche de zéro. L’investissement se transforme donc en charges : « Tant que le client ne démarre pas son PRA, il n’y pas de licence à payer aux fournisseurs ; seules des ressources matérielles sont mises à disposition ».
En résumé, la définition du PRA dépend des objectifs de sécurité que l’organisation se fixe : « Lorsqu’une reprise sous un à cinq jours convient, une simple sauvegarde suffit. Mais si on doit assurer une restauration complète sous 4 heures, il faut ajouter des mécanismes de réplication synchrone et quelques zéros à la facture », reconnaît-il. Pour reconstruire certaines transactions critiques, on peut aussi repartir de snapshots ou rejouer les dernières étapes des journaux systèmes.
Plus que des recettes de virtualisation ou d’automatisation, le socle d’infrastructure doit devenir tangible et résilient.
Le mécanisme de reprise d’activités
PDMA Perte de données maximale admissible
RPO Recovery point objective, objectif quantitatif de données perdues
DMIA Durée maximale d’interruption admissible
RTO Recovery time objective, objectif de reprise après incident
AVIS D’EXPERT
Francis Brisedoux,
manager IT d’ASL Airlines France.
ASL Airlines France retient Rubrik
pour ses restaurations instantanées
« Ceinture, bretelles et parachute », qualifie Francis Brisedoux, le manager IT d’ASL Airlines France. La compagnie aérienne, héritière de l’Aéropostale, protège efficacement le socle informatique de ses activités de fret et de transport de passagers, assurées par la rotation de 17 Boeing 737.
Elle a choisi le soutien de l’éditeur Rubrik pour mener les sauvegardes compressées, dédupliquées et chiffrées de machines virtuelles (VM) sur plusieurs sites, en Cloud privé, sur un site de PRA, chez OVH, puis Amazon Web Services au-delà d’un mois. Pour garantir les niveaux de services des VM, quatre fréquences de sauvegarde sont retenues avec leur propre règle de rétention.
« L’assurance tous risques d’une DSI, c’est d’avoir des sauvegardes fiables et performantes », souligne le manager. Son équipe IT, composée de 6 personnes pour 250 serveurs, épaule 450 salariés dans la filiale française. Dès 2009, elle met le cap sur l’industrialisation de l’infrastructure avec la virtualisation des serveurs sous VMware, puis celle des postes VDI en 2011, l’hyperconvergence avec Nutanix en 2013, la ToIP dans le Cloud en 2014, et le nouveau PRA avec Rubrik en 2017.