








Le CERN a testé positivement l’Oracle Autonomous Data Warehouse Cloud afin de réaliser plus facilement l’analyse en temps réel de données de contrôle en gros volume et sur longue période.
Le Conseil Européen pour la Recherche Nucléaire (CERN), fondé en 1954 par 12 pays, est à la pointe de la recherche en physique fondamentale. Il compte 23 Etats membres et emploie 2 300 salariés. Le complexe d’accélérateurs du CERN est une chaîne de machines qui accélèrent les particules à des énergies croissantes, dont le plus connu est le Grand collisionneur de hadrons (LHC). En plus des données scientifiques (30 PB/an), le CERN produit 2,5 TB par jour de données de contrôle : détecteurs, accélérateurs, infrastructure technique.
CALS et NX CALS
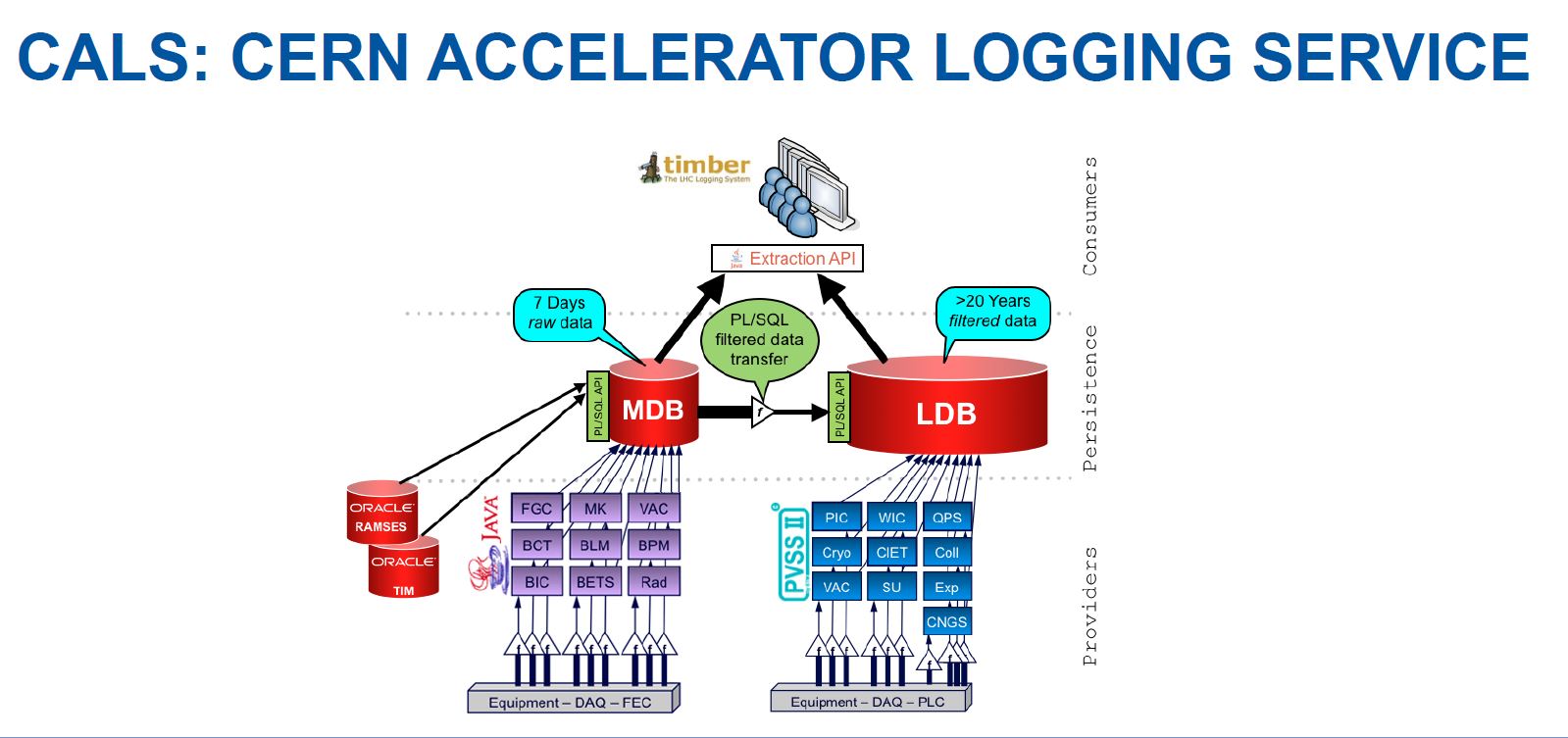
Le deux bases de données principales relatives à ces données de contrôle forment le CERN Accelerator Logging Service (CALS). La première est la Measurement DataBase (MDB), un buffer de 20 TB qui vient récolter tous les signaux émis par certains équipements (données brutes sur sept jours). Les données sont filtrées puis transférées au Logging DataBase (LDB). Cette seconde base de données d’un PB reçoit aussi les éléments en direct n’ayant pas besoin d’être filtrés. Elle contient plus de vingt ans de données.

« Elles reposent sur une technologie robuste et une architecture simple, permettant une analyse en temps réel sur quelques jours ou quelques semaines à des fins de contrôle de l’accélérateur, explique Sébastien Masson, administrateur de bases de données au CERN. Ce système conçu il y a longtemps n’est toutefois pas très satisfaisant en termes de performance, en particulier pour des jeux de données plus volumineux, faire des recherches historiques ou des analyses de tendances. »
Aussi a été mise en place une plateforme Hadoop, Next Génération CALS (NXCALS) pour faire des analyses plus approfondies. Mais, mélangeant des technologies complexes, elle demande des efforts de développement et d’administration, et ne permet pas l’accès temps réel.
Un système autonome, Big Data et temps réel
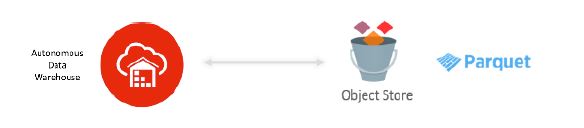
Or le CERN a souhaité réaliser une analyse approfondie des données historiques en gros volume et en temps réel. Il teste cette possibilité grâce à Openlab, le partenariat public-privé à travers lequel il collabore avec de grandes entreprises IT et d’autres organisations de recherche, dont Oracle depuis 2003. Les objectifs d’Openlab sont d’accélérer la mise au point des technologies informatiques de pointe pour la communauté de recherche du LHC et de former la prochaine génération d’ingénieurs et de chercheurs. Sébastien Masson indique : « Nous avons testé la performance l’entrepôt de données autonomes (Autonomous Data Warehouse) d’Oracle, qui utilise l’infrastructure Exadata, à partir de septembre 2019. Nous l’avons effectué sur un jeu représentatif de données du système électrique. On peut charger des données dans la base de données et des fichiers au format Parquet directement dans un stockage objet annexe (Object Store) et y accéder depuis la base de données en créant des tables externes. Nous travaillons avec des développeurs d’ADW à San Francisco sur le partitionnement hybride : des tables ont des données dans la base de données et dans l’Object Store tout en permettant d’y accéder de manière transparente. »
Les premiers résultats sont satisfaisants, selon Sébastien Masson : « C’est un système autonome. Il ne requiert notamment pas de patching de la part des administrateurs de bases de données. Le déploiement des instances est rapide. Il fait gagner du temps, en permettant de lire uniquement les fichiers Parquet pertinents. Il a le même niveau de performance que sur l’ancien système CALS sur plusieurs scénarios, ce qui a validé l’analyse temps réel. Les utilisateurs, qui sont les opérateurs qui paramètrent, surveillent et maintiennent les accélérateurs, peuvent utiliser l’outil Oracle Analytics Cloud afin d’être autonomes sur la génération de leurs tableaux de bord et de contrôle. »
Avec cet outil unique à la fois autonome, temps réel et orienté big data, les administrateurs de bases de données peuvent fournir des données accessibles plus facilement aux utilisateurs et se dégager du temps pour d’autres tâches. En 2020, la phase d’étude se poursuit sur le partitionnement en fonction de différentes structures de données types et des jeux complets de données sur des périodes plus longues. « Dans l’hypothèse d’adoption d’ADW, il deviendrait un système complémentaire aux systèmes actuels qui simplifierait l’analyse fine des données sur longue période, » conclut Sébastien Masson.
Le CERN a la tête dans les nuages
Le CERN a également testé de façon satisfaisante le Cloud Oracle pour réaliser des calculs à des fins d’analyse de données de physique : l’entreprise IT américaine a fourni 10 000 cœurs de processeurs sur l’infrastructure Oracle Cloud pour la grande grille informatique mondiale du LHC. Le Cloud Oracle est interconnecté avec le réseau GEANT utilisé dans le milieu de la recherche.
Par ailleurs, pour l’enregistrement des 90 000 visiteurs de ses trois journées de portes ouvertes en septembre 2019, le CERN s’est aussi appuyé sur le Cloud Oracle. L’organisation a développé en moins de trois mois une application cloud multidevice.
Eric Grancher, directeur des services de bases de données au CERN, en explique les objectifs : mieux gérer le flux de visiteurs, offrir de nouveaux services aux visiteurs lors de l’événement, gagner du temps grâce à l’automatisation permise par les services cloud.
Auteur : Christine Calais




